
RxJava 沉思录:用了这么久,你认为 RxJava 真的好用吗?
本人两年前第一次接触 RxJava,和大多数初学者一样,看的第一篇 RxJava 入门文章是扔物线写的《给 Android 开发者的 RxJava 详解》,这篇文章流传之广,相信几乎所有学习 RxJava 的开发者都阅读过。尽管那篇文章定位读者是 RxJava 入门的初学者,但是当时阅读完之后还是觉得懵懵懂懂,总感觉依然不是很理解这个框架设计理念以及优势。
随后工作中有机会使用 RxJava 重构了项目的网络请求以及缓存层,期间陆陆续续又重构了数据访问层,以及项目中一些其他的功能模块,无一例外,我们都选择使用了 RxJava 。
最近翻看一些技术文章,发现涉及 RxJava 的文章还是大多以入门为主,我尝试从一个初学者的角度阅读,发现很多文章都没讲到关键的概念点,举的例子也不够恰当。回想起两年前刚刚学习 RxJava 的自己,虽然看了许多 RxJava 入门的文章,但是始终无法理解 RxJava 究竟好在哪里,所以一定是哪里出问题了。于是有了这一篇反思,希望和你一起重新思考 RxJava,以及重新思考 RxJava 是否真的让我们的开发变得更轻松。
观察者模式有那么神奇吗?
几乎所有 RxJava 入门介绍,都会用一定的篇幅去介绍 “观察者模式”,告诉你观察者模式是 RxJava 的核心,是基石:
1 | observable.subscribe(new Observer<String>() { |
年少的我不明觉厉:“好厉害,原来这是观察者模式”,但是心里还是感觉有点不对劲:“这代码是不是有点丑?接收到数据的回调名字居然叫 onNext ? ”
但是其实观察者并不是什么新鲜的概念,即使你是新手,你肯定也已经写过不少观察者模式的代码了,你能看懂下面一行代码说明你已经对观察者模式了然于胸了:
1 | button.setOnClickListener(v -> doSomething()); |
这就是观察者模式,OnClickListener 订阅了 button 的点击事件,就这么简单。原生的写法对比上面 RxJava 那一长串的写法,是不是要简单多了。有人可能会说,RxJava 也可以写成一行表示:
1 | RxView.clicks(button).subscribe(v -> doSomething()); |
先不说这么写需要引入 RxBinding 这个第三方库,不考虑这点,这两种写法最多也只是打个平手,完全体现不出 RxJava 有任何优势。
这就是我要说的第一个论点,如果仅仅只是为了使用 RxJava 的观察者模式,而把原先 Callback 的形式,改为 RxJava 的 Observable 订阅模式是没有价值的,你只是把一种观察者模式改写成了另一种观察者模式。我是实用主义者,使用 RxJava 不是为了炫技,所以观察者模式是我们使用 RxJava 的理由吗?当然不是。
链式编程很厉害吗?
链式编程也是每次提到 RxJava 的时候总会出现的一个高频词汇,很多人形容链式编程是 RxJava 解决异步任务的 “杀手锏”:
1 | Observable.from(folders) |
这段代码出现的频率非常的高,好像是 RxJava 的链式编程给我们带来的好处的最佳佐证。然而平心而论,我看到这个例子的时候,内心是平静的,并没有像大多数文章写得那样,内心有“它很长,但是很清晰”的心理活动。
首先,flatMap, filter, map 这几个操作符,对于没有函数式编程经验的初学者来讲,并不好理解。其次,虽然这段代码用了很多 RxJava 的操作符,但是其逻辑本质并不复杂,就是在后台线程把某个文件夹里面的以 png 结尾的图片文件解析出来,交给 UI 线程进行渲染。
上面这段代码,还带有一个反例,使用 new Thread() 的方式实现的版本:
1 | new Thread() { |
对比两种写法,可以发现,之所以 RxJava 版本的缩进减少了,是因为它利用了函数式的操作符,把原本嵌套的 for 循环逻辑展平到了同一层次,事实上,我们也可以把上面那个反例的嵌套逻辑展平,既然要用 lambda 表达式,那肯定要大家都用才比较公平吧:
1 | new Thread(() -> { |
坦率地讲,这段代码除了 new Thread().start() 有槽点以外,没什么大毛病。RxJava 版本确实代码更少,同时省去了一个中间变量 pngFiles,这得益于函数式编程的 API,但是实际开发中,这两种写法无论从性能还是项目可维护性上来看,并没有太大的差距,甚至,如果团队并不熟悉函数式编程,后一种写法反而更容易被大家接受。
回到刚才说的“链式编程”,RxJava 把目前 Android Sdk 24 以上才支持的 Java 8 Stream 函数式编程风格带到了带到了低版本 Android 系统上,确实带给我们一些方便,但是仅此而已吗?到目前为止我并没有看到 RxJava 在处理事件尤其是异步事件上有什么特别的手段。
准确的来说,我的关注点并不在大多数文章鼓吹的“链式编程”这一点上,把多个依次执行的异步操作的调用转化为类似同步代码调用那样的自上而下执行,并不是什么新鲜事,甚至 Android 的 Handler - Looper 模式就可以实现:
1 | handler.post(() -> task1()); |
我相信把 Handler - Looper 这种模式进行封装一下变成一个新的库,也可以和上面的 RxJava 的例子变得差不多好用。
除此以外,对于处理异步任务,还有 Promise 这个流派,使用类似这样的 API:
1 | promise |
难道不是比 RxJava 更加简洁直观吗?而且还不需要引入函数式编程的内容。所以从目前看来,RxJava 在我心目是是个 “哦,还挺不错” 的框架,但是并没有惊艳到我。所以我想,聪明的你,下次再听到有人吹嘘所谓的“链式编程”,你大概只需要微微一笑就可以了。
另外,值得提一点,如果用了 RxJava 的话,框架会自动帮你维护线程池,而且线程切换起来很方便,这个倒是学习 RxJava 的意外收获。
以上是我要说的第二个论点,链式编程只是一种语法糖,通过链式把嵌套逻辑展平。这只是普通操作,也有其他框架可以做到相似效果。
RxJava 等于异步加简洁吗?
相信阅读过本文开头介绍的那篇 RxJava 入门文 《给 Android 开发者的 RxJava 详解》 的开发者一定对文中两个小标题印象深刻:
RxJava 到底是什么? —— 一个词:异步
RxJava 好在哪? —— 一个词:简洁
首先感谢扔物线,很用心地为初学者准备了这篇简洁朴实的入门文。但是我还是想要指出,这样的表达是不够严谨的。
虽然我们使用 RxJava 的场景大多数与异步有关,但是这个框架并不是与异步等价的。举个简单的例子:
1 | Observable.just(1,2,3).subscribe(System.out::println); |
上面的代码就是同步执行的,和异步没有关系。事实上,RxJava 除非你显式切换到其他的 Scheduler,或者你使用的某些操作符隐式指定了其他 Scheduler,否则 RxJava 相关代码就是同步执行的。
这种设计和这个框架的野心有关,RxJava 是一种新的 事件驱动型 编程范式,它以异步为切入点,试图一统 同步 和 异步 的世界。
本文前面提到过:
RxJava 把目前 Android Sdk 24 以上才支持的 Java 8 Stream 函数式编程风格带到了带到了低版本 Android 系统上。
所以只要你愿意,你完全可以在日常的同步编程上使用 RxJava,就好像你在使用 Java 8 的 Stream API。( 但是两者并不等价,因为 RxJava 是事件驱动型编程 )
如果你把你日常的同步编程,封装为同步事件的 Observable,那么你会发现,同步和异步这两种情况被 RxJava 统一了, 两者具有一样的接口,可以被无差别的对待,同步和异步之前的协作也可以变得比之前更容易。
所以,到此为止,我这里的结论是:RxJava 不等于异步。
那么 RxJava 等于 简洁 吗?我相信有一些人会说 “是的,RxJava 很简洁”,也有一些人会说 “不,RxJava 太糟糕了,一点都不简洁”。这两种说法我都能理解,其实问题的本质在于对 简洁 这个词的定义上。关于这个问题,后面会有一个小节专门讨论,但是我想提前先下一个结论,对于大多数人,RxJava 不等于简洁,有时候甚至是更难以理解的代码以及更低的项目可维护性。
RxJava 是用来解决 Callback Hell 的吗?
很多 RxJava 的入门文都宣扬:RxJava 是用来解决 Callback Hell (有些翻译为“回调地狱”)问题的,指的是过多的异步调用嵌套导致的代码呈现出的难以阅读的状态。
我并不赞同这一点。Callback Hell 这个问题,最严重的重灾区是在 Web 领域,是使用 JavaScript 最常见的问题之一,以至于专门有一个网站 callbackhell.com 来讨论这个问题,由于客户端编程和 Web 前端编程具有一定的相似性,Android 编程也存在这个问题。
上面这个网站中,介绍了几种规避 Callback Hell 的常见方法,无非就是把嵌套的层次移到外层空间来,不要使用匿名的回调函数,为每个回调函数命名。如果是 Java 的话,对应的,避免使用匿名内部类,为每个匿名内部类的对象,分配一个对象名。当然,也可以使用框架,类似 Promise 那样的专门为异步编程打造的框架,Android 平台上也有类似的开源版本 jdeferred。
在我看来,jdeferred 那样的框架,更像是那种纯粹的用来解决 Callback Hell 的框架。 至于 RxJava,前面也提到过,它是一个更有野心的框架,正确使用了 RxJava 的话,确实不会有 Callback Hell 再出现了,但如果说 RxJava 就是用来解决 Callback Hell 的,那就有点高射炮打蚊子的意味了。
如何理解 RxJava
也许阅读了前面几小节内容之后,你的心中会和曾经的我一样,对 RxJava 产生一些消极的想法,并且会产生一种疑问:那么 RxJava 存在的意义究竟是什么呢?
举几个常见的例子:
为 View 设置点击回调方法:
1
2
3
4
5
6btn.setOnClickListener(new OnClickListener() {
public void onClick(View v) {
// callback body
}
});Service 组件绑定操作:
1
2
3
4
5
6
7
8
9
10
11
12
13private ServiceConnection mConnection = new ServiceConnection() {
public void onServiceConnected(ComponentName className, IBinder service) {
// callback body
}
public void onServiceDisconnected(ComponentName arg0) {
// callback body
}
};
...
bindService(intent, mConnection, Context.BIND_AUTO_CREATE);使用 Retrofit 发起网络请求:
1
2
3
4
5
6
7
8
9
10
11Call<List<Photo>> call = service.getAllPhotos();
call.enqueue(new Callback<List<Photo>>() {
public void onResponse(Call<List<Photo>> call, Response<List<Photo>> response) {
// callback body
}
public void onFailure(Call<List<Photo>> call, Throwable t) {
// callback body
}
});
在日常开发中我们时时刻刻在面对着类似的回调函数,而且容易看出来,回调函数最本质的功能就是把异步调用的结果返回给我们,剩下的都是大同小异。所以我们能不能不要去记各种各样的回调函数,只使用一种回调呢?如果我们定义统一的回调如下:
1 | public class Callback<T> { |
那么以上 3 种情况,对应的回调变成了:
- 为 View 设置点击事件对应的回调为
Callback<View> - Service 组件绑定操作对应的回调为
Callback<Pair<CompnentName, IBinder>>(onServiceConnected)、Callback<CompnentName>(onServiceDisconnected) - 使用 Retrofit 发起网络请求对应的回调为
Callback<List<Photo>>(onResponse)、Callback<Throwable>(onFailure)
只要按照这种思路,我们可以把所有的异步回调封装成 Callback<T> 的形式,我们不再需要去记忆不同的回调,只需要和一种回调交互就可以了。
写到这里,你应该已经明白了,RxJava 存在首先最基本的意义就是 统一了所有异步任务的回调接口 。而这个接口就是 Observable<T>,这和刚刚的 Callback<T> 其实是一个意思。此外,我们可以考虑让这个回调更通用一点 —— 可以被回调多次,对应的,Observable 表示的就是一个事件流,它可以发射一系列的事件(onNext),包括一个终止信号(onComplete)。
如果 RxJava 单单只是统一了回调的话,其实还并没有什么了不起的。统一回调这件事情,除了满足强迫症以外,额外的收益有限,而且需要改造已有代码,短期来看属于负收益。但是 Observable 属于 RxJava 的基础设施,有了 Observable 以后的 RxJava 才刚刚插上了想象力的翅膀。
Observable 在空间维度上重新组织事件的能力
情景一:有一个相册应用,从网络获取当前用户的照片列表,展示在 RecyclerView 里:
1 | public interface NetworkApi { |
上面是使用 Retrofit 定义的从网络获取照片的 API 的接口。大家都知道,如果我们使用 Retrofit 的 RxJavaCallAdapter 就可以把接口中的返回从 Call<List<Photo>> 转为 Observable<List<Photo>>:
1 | public interface NetworkApi { |
那么我们使用这个接口展示照片的代码应该长下面这样:
1 | NetworkApi networkApi = ... |
现在新加一个需求,请求当前用户照片列表这个网络请求,需要加入缓存功能(缓存的是网络响应中的图片的URL,图片的 Bitmap 缓存交给专门的图片加载框架,例如 Glide),也就是说,当用户希望展示图片列表时,先去缓存读取用户的照片列表进行加载(如果缓存里有这个接口的上次访问的数据),同时发起网络请求,待网络请求返回之后,更新缓存,同时使用使用最新的返回数据刷新照片列表。如果我们选择使用 JakeWharton 的 DiskLruCache 作为我们的缓存介质,那么上面的代码将变为:
1 | DiskLruCache cache = ... |
上面的代码就是最直观的可以解决需求的代码,我们进一步思考一下,读取文件缓存也属于耗时操作,我们最好把它封装为异步任务,既然网络请求已经被封装成 Observable 了,我们尝试把读取文件缓存也封装为 Observable:
1 | Observable<List<Photo>> cachedObservable = Observable.create(emitter -> { |
到目前为止,发起网络请求和读取缓存这两个异步操作都被我们封装成了 Observable 的形式,前面做了这么多铺垫,接下来进入正题,把原先的面向 Callback 的异步操作统一改写为 Observable 的形式以后,首先带来的好处就是可以对 Observable 在空间维度上进行重新组织。
1 | networkApi.getAllPhotos() |
调用
startWith操作符后,会生成一个新的 Observable,新的 Observable 会首先发射传入的 Observable 包含的元素,而后才会发射原来的 Observable 包含的元素。例如 Observable A 包含 a1, a2 两个元素, Observable B 包含 b1, b2 两个元素,那么 b.startWith(a) 返回的新 Observable 发射序列顺序为: a1, a2, b1, b2。—— 参考资料:StartWith
在上面的例子中,我们连接了网络请求和读取缓存这两个 Observable,原先需要分别处理结果的两个异步任务,我们现在把它们结合成了一个,指定了一个观察者就满足了需求。这个观察者会被回调 2 次,第一次是来自缓存的结果,第二次是来自网络的结果,体现在界面上就是列表刷新了两次。
这里引发了我们的思考,原先 Callback 的写法,如果我们有 n 个异步任务,我们就需要指定 n 个回调;而如果在 n 个异步任务都已经被封装成 Observable 的情况下,我们就可以对 Observable 进行分类、组合、变换,经过这样的处理以后,我们的观察者的数量就会减少,而且职责会变的简单而直接,只需要对它所关心的数据类型做出响应,而不需要关心数据从何而来,经历过怎样的变化。
我们再进一步,上面的例子再加一个需求:如果从网络请求回来的数据和缓存中提前响应的数据一致,就不需要再刷新一次了。也就是说,如果缓存数据和网络数据一致,那缓存数据刷新一次列表以后,网络数据不需要再去刷新一次列表了。
我们考虑一下,如果我们使用传统 Callback 的形式,指定了两个 Callback 去处理这个需求,为了保证第二次网络请求回来的相同数据不刷新,我们势必需要在两个 Callback 之外,定义一个变量来保存缓存数据,然后在网络请求的回调内,比较两个值,来决定是否需要刷新界面。
如果我们用 RxJava 如何来实现这个需求,该如何写呢:
1 | networkApi.getAllPhotos() |
distinctUntilChanged操作符用来确保 Observable 发射的元素里,相邻的两个元素必须是不相等的。 参考资料:Distinct
与原先的写法相比,只多了一行 .distinctUntilChanged() ( 我们假设用于比较两个对象是否相等的 equals 方法已经实现 ),就可以满足,在网络数据和缓存数据一致的情况下,观察者只回调一次。
我们比较一下使用 Callback 的写法和使用 Observable 进行组装的写法,可以发现,使用 Callback 的写法,经常会由于需求的变化,导致 Callback 内部的逻辑发生变动,而使用 Observable 的写法,观察者的核心逻辑则较为稳定,很少发生变化(本例中为刷新列表)。Observable 通过内置的操作符对自身发射的元素在空间维度上重新组织,或者与其他的 Observable 一起在空间维度上进行重新组织,使得观察者的逻辑简单而直接,不需要关心数据从何而来,从而使观察者的逻辑较为稳定。
下面是一个比较复杂的例子。
情景二:实现一个具有多种类型的 RecyclerView,如图所示:
假设列表中有 3 种类型的数据,这 3 种类型共同填充了一个 RecyclerView,简单起见,我们定义 Retrofit 接口如下:
1 | public interface NetworkApi { |
到目前为止,情况还是简单的, 我只要维护 3 个 RecyclerView 并分别各自更新即可。但是我们现在接到新加需求,这 3 种类型的数据在列表中出现的顺序是可配置的,而且 3 种类型数据不一定全部需要展示,也就是说可能展示 3 种,也可能只展示其中 2 种。我们定义与之对应的接口:
1 | public interface NetworkApi { |
新加的 getColumns 接口,返回的数据形如:
["a", "b", "c"]["b", "a"]["b", "c"]
首先考虑使用普通的 Callback 形式如何来实现这个需求。由于 3 种数据现在顺序可变,数量也无法确定,如果还是考虑由多个 RecyclerView 来维护的话需要在布局中调用 addView, removeView
来添加移除 RecyclerView,这样的话性能上不够好,我们考虑把所有数据填充到一个 RecyclerView 中,不同类型的数据通过不同 ItemType 进行区分。下面的代码中我依然使用了 Observable ,只是我仅仅把它当成普通的 Callback 功能使用:
1 | private NetworkApi networkApi = ... |
上面的代码,为了避免 Callback Hell 出现,我已经提前把 onOk 提到了外部层次,使代码便于从上往下阅读。但是不知道你有没有和我相同的感觉,就是类似这样的代码总给人一种不是很 “内聚” 的感觉,就是为了把 Callback 展平,导致一些中间变量被暴露到了外层空间。
带着这个问题,我们先分析一下数据流动:
refresh方法发起第一次请求,得到需要被展示的 n 种数据的类型以及顺序。- 根据第一次请求的结果,发起 n 次请求,分别得到每种数据的结果。
onOk方法作为观察者, 会被回调 n 次,按照第一个接口里返回的顺序正确的汇总 2 中每个数据接口返回的结果,并且通知界面更新。
有点像写作文一样,这是一种 总——分——总 的结构。
接下来我们使用 RxJava 来实现这个需求,我们会用到 RxJava 的一些操作符,来对 Observable 进行重新组织:
1 | NetworkApi networkApi = ... |
我们一步一步分析 RxJava 处理的具体步骤。首先是第一步,获取需要展示的栏目列表,这是最简单的,networkApi.getColumns() 这个方法返回是一个只发射一个元素的 Observable,这个元素即为展示的栏目列表,为了方便后续讨论,假设栏目的顺序为 ["a", "b", "c"], 如下图所示:

接下来的操作符是 map 操作符,原来的 Observable 进行了变换,变成了一个新的 Observable,新的 Observable 还是只发射一个元素,这个元素的类型还是 List ,只不过 List 内部的数据类型从原先的字符串(代表数据类型)变成了 Observable。Observable 发射的元素还可以是 Observable 的 List 吗?是的,没有什么不可以 : )
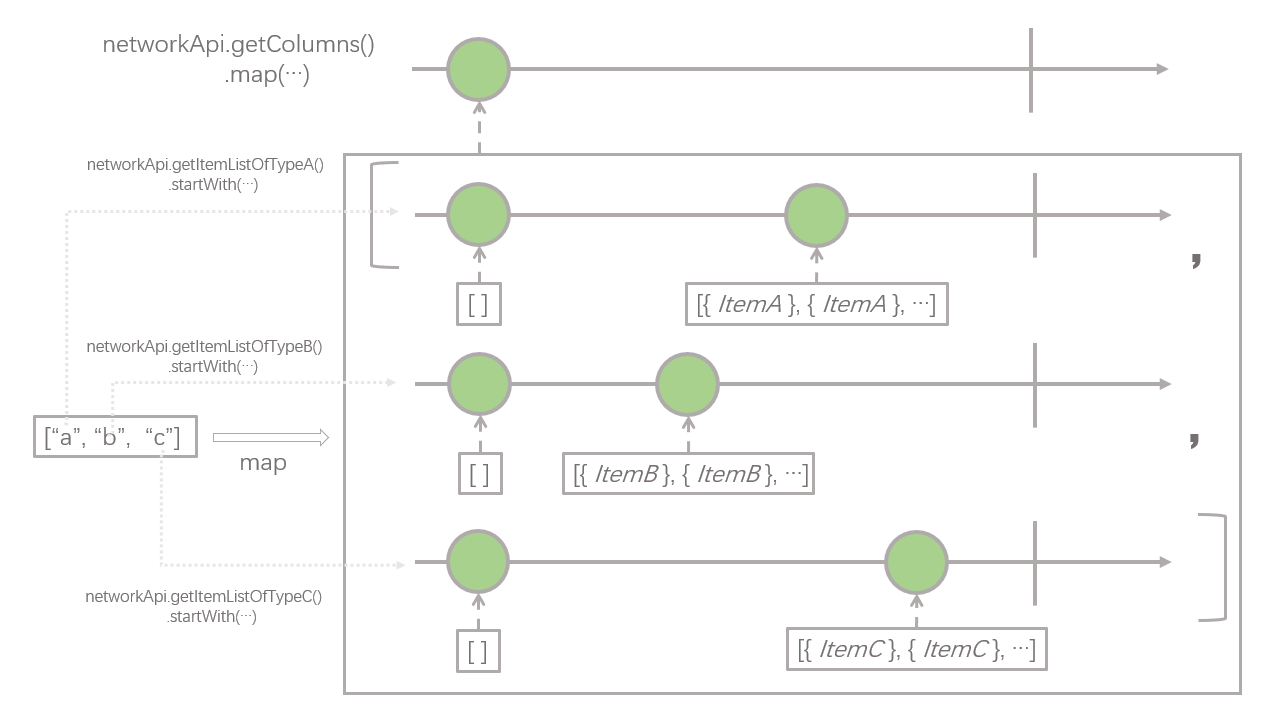
map操作符负责把一个Observable里发射的元素全部进行转换,生成一个发射新的元素的Observable,元素的种类会发生改变,但是发射的元素的数量不会发生改变。 参考资料:Map
这个操作,在业务上的含义是,根据上一步取回的栏目列表,即 ["a", "b", "c"],根据不同的数据类型,分别发起请求去获取对应栏目的数据列表,例如栏目类型是 a 的话,就对应发起 networkApi.getItemListOfTypeA() 请求。这里有一点值得注意,就是每一个具体的请求后面都跟了一个 .startWith(new ArrayList<>()),也就是说每个具体请求栏目内容的 Observable 在返回真正的数据 List 之前都会返回一个空的 List ,这里这么处理的原因我们会在下一步中解释。
接下来这一步可能是最难理解的一步了,map 操作之后,紧接着是 flatMap 操作符,而 flatMap 操作符传入的 lambda 表达式内部,又调用了 Observable.combineLatest 操作符,我们先从里面的 combineLatest 操作符开始讲起,请看下图:
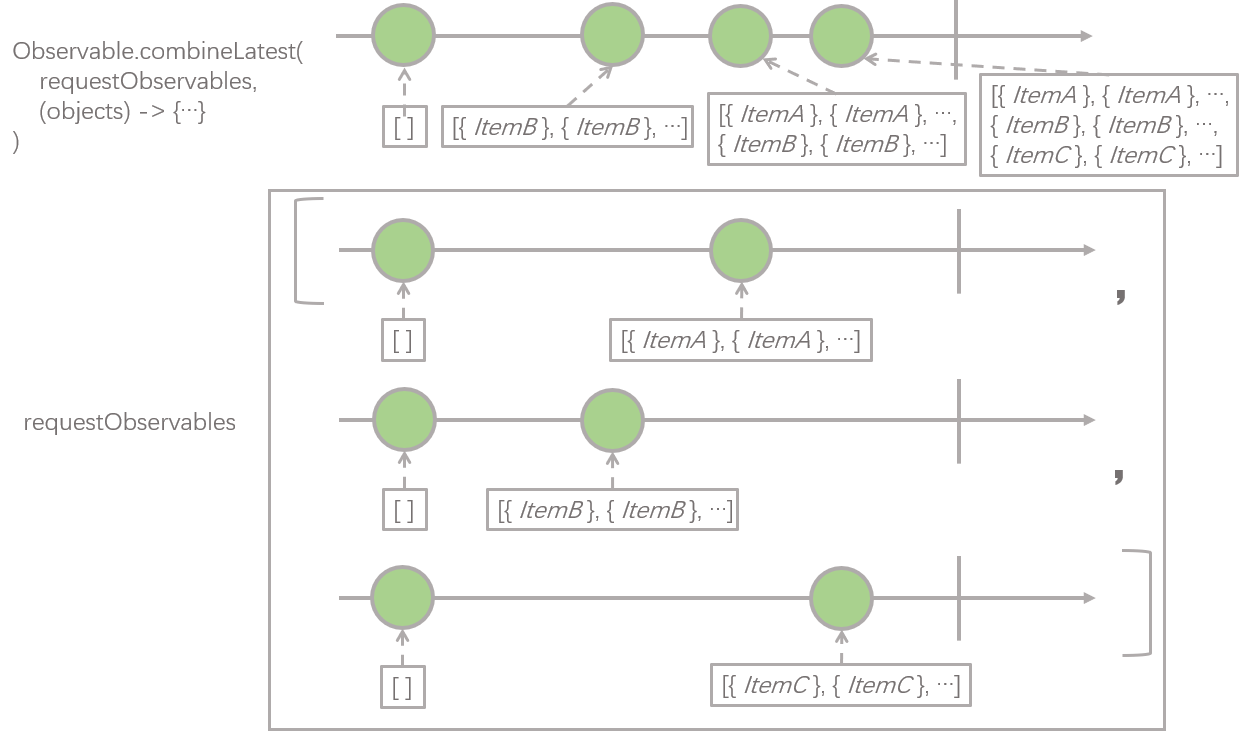
combineLatest 操作符的第一个参数 requestObservables,它的类型是 Observable 的 List,它就是上一步中 map 操作符进行变换之后,新的 Observable 发射的数据,即由
networkApi.getItemListOfTypeA().startWith(...)networkApi.getItemListOfTypeB().startWith(...)networkApi.getItemListOfTypeC().startWith(...)
3 个 Observable 组成的 List。
combineLatest 操作符的第二个参数是个 lambda 表达式,这个 lambda 表达式的参数类型是 Object[],这个数组的长度等于 requestObservables 的长度,Object[] 数组中每个元素即为 requestObservables 中每个 Observable 发射的元素,即:
Object[0]对应requestObservables[0]发射的元素Object[1]对应requestObservables[1]发射的元素Object[2]对应requestObservables[2]发射的元素
那这个 lambda 表达式被调用的时机是什么时候呢?当 requestObservables 中任意一个 Observable 发射一个元素时,这个元素便会和 requestObservables 中剩余的所有 Observable 最近一次 发射的元素一起,作为参数调用这个 lambda 表达式。
那么整个 combineLatest 操作符的作用就是,返回一个新的 Observable, 根据第一个参数里输入的一组 Obsevable,按照上面说的时机,调用第二个参数里的那个 lambda 表达式,把这个 lambda 表达式的返回值,作为新的 Observable 发射的值,lambda 被调用几次,就发射几个元素。
我们这里 lambda 表达式内部的逻辑比较简单,就是把 3 个接口里返回的数据进行汇总,组成一个新的 List 。我们再回过头看上面那张图,我们可以看到,Observable.combinLatest 返回的新的 Observable 一共发射了 4 个元素,它们分别是:
[][{ItemB}, {ItemB}, ...][{ItemA}, {ItemA}, ..., {ItemB}, {ItemB}, ...][{ItemA}, {ItemA}, ..., {ItemB}, {ItemB}, ..., {ItemC}, {ItemC}, ...]
前面留了一个问题没有解释,为什么 3 个获取具体的栏目数据的接口需要调用 startWith 操作符发射一个空白列表,就像这样:networkApi.getItemListOfTypeA().startWith(...),现在这个答案应该清晰了,如果不调用这个操作符,那么 combineLatest 操作符生成的新 Observable 将会只发射一个元素, 即上面 4 个元素的最后一个,从用户的感受来看,必须要等所有栏目全部请求成功以后才会一次性展示,而不是渐进地展示。
说完了内部的 combineLatest 操作符,现在该说外层的 flatMap 操作符了,flatMap 操作符也会生成一个新的 Observable,它会通过传入的 lambda 表达式,把旧的 Observable 里发射的每一个元素都映射成一个 Observable,然后把这些 Observable 发射的所有元素作为新的 Observable 发射的元素。
由于我们这里的情况,调用 flatMap 之前的 Observable 只发射了一个元素,所以 flatMap 之后生成的新 Observable 发射的元素,就是 flatMap 操作符传入的那个 lambda 表达式执行完生成的那个 Observable 所发射的元素,也就是说 flatMap 操作符执行完后的那个新的 Observable 发射的元素,和我们刚刚讨论的 combineLatest 操作符执行完后的 Observable 发射的元素是一致的。
到这里为止,RxJava 实现的版本的每一步我们都解释完了,我们回过头重新梳理一下 RxJava 对 Observable 进行变换的过程,如下图:
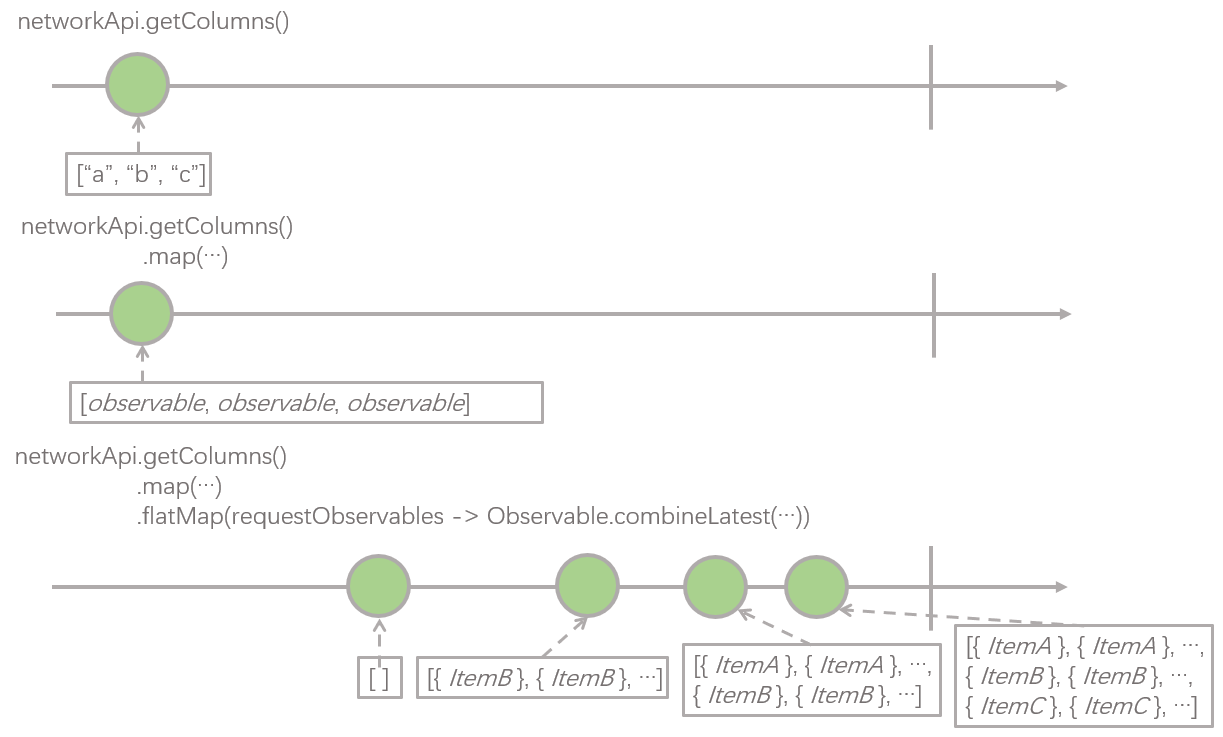
通过 RxJava 的操作符,我们把 networkApi 里的 4 个接口返回的 4 个 Observable,在空间维度进行了重新组织,最终把它们转成了一个 Observable,这个 Observable 发射的元素类型是 List<Item>,而这正是我们的观察者 – Adapter 所关心的数据类型,观察者只需要监听这个 Observable ,并更新数据即可。
我们在讲 RxJava 实现的这个版本之前的时候,说到过 Callback 实现的版本不够 内聚,比较一下现在这个 RxJava 的版本,确实可以发现的确 RxJava 这个版本更内聚。但是并非 Callback 版本没有办法做到更内聚,我们可以把 Callback 版本里的 onOk, refresh,resultTypes, responseList 这几个方法和字段封装到一个对象中,对外只暴露 refresh 方法和设置观察的方法,也可以做到一样的内聚,但是这就需要额外的工作量了。但是如果我们使用 RxJava 就不一样了,它提供了一堆现成的操作符,通过 Observable 之间的变换与重组,直接就可以写出内聚的代码。
在上面代码里出现的所有操作符中,最核心的一个操作符就是 combineLatest 操作符,仔细比较 RxJava 版本和 Callback 版本就可以发现,combineLatest 操作符的功能其实和 Callback 版本里的 onOk 方法前半部分, resultTypes, responseList 功能是相当的,一方面负责收集多个接口返回的数据,另一方面保证收集回来的数据的顺序是和上一个接口返回的应该展示的数据的顺序是一致的。
从代码量上来看,RxJava 版本与 Callback 版本相差无几,对函数式编程比较擅长的人来说,RxJava 版本里 for 循环的写法,不够 “函数式”,我们可以把原来的写法改成一种更紧凑、更函数式的写法:
1 | NetworkApi networkApi = ... |
这里引入了一个新的操作符
collectInto,用于把一个 Observable 里面发射的元素,收集到一个可变的容器内部,本例中用它来替换for循环相关逻辑,具体内容这里不再详细展开。
参考资料:CollectInto
这个例子花了这么大篇幅来讲,超出了我一开始的预期,这也可以看出来的确 RxJava 学习的曲线是陡峭的,不过我认为这个例子很好的表达我这一小节要阐述的观点,即 Observable 在空间维度上对事件的重新组织,让我们的事件驱动型编程更具想象力 ,因为原先的编程中,我们面对多少个异步任务,就会写多少个回调,如果任务之间有依赖关系,我们的做法就是修改观察者(回调函数)逻辑以及新增数据结构保证依赖关系,RxJava 给我们带来的新思路是,Observable 在到达观察者之前,可以先通过操作符进行一系列变换(当然变换的规则还是和具体业务逻辑有关的),对观察者屏蔽数据产生的复杂性,只提供给观察者简单的数据接口。
那么是否在这个例子中,RxJava 的版本更好呢,我个人的观点是虽然 RxJava 版本展现了其更有想象力的编程方式,但是就这个具体的例子,两者并没有太大的差距。RxJava 可以写出更短更内聚的代码,但是编写和理解的难度较大;Callback 版本虽然朴实无华,但是便于编写以及理解,可维护性更好。对于两者的好坏,我们也不要过于着急下结论,不妨继续看看 RxJava 还有什么其他优势。
Observable 在时间维度上的重新组织事件的能力
情景一:点击事件防抖动
这是一个比较常见的情景,用户在手机比较卡顿的时候,点击某个按钮,正常应该启动一个页面,但是手机比较卡,没有立即启动,用户就点了好几下,结果等手机回过神来的时候,就会启动好几个一样的页面。
这个需求用 Callback 的方式比较难处理,但是相信用过 RxJava 的开发者都知道怎么处理:
1 | RxView.clicks(btn) |
debounce操作符产生一个新的Observable, 这个Observable只发射原Observable中时间间隔小于指定阈值的最大子序列的最后一个元素。 参考资料:Debounce
虽然这个例子比较简单,但是它很好的表达了 Observable 可以在时间维度上对其发射的事件进行重新组织 , 从而做到之前 Callback 形式不容易做到的事情。
情景二:社交软件上消息的点赞与取消点赞
点赞与取消点赞是社交软件上经常出现的需求,假设我们目前有下面这样的点赞与取消点赞的代码:
1 | boolean like; |
以下图片素材资源来自 Dribbble
如果你碰巧实现了一个非常酷炫的点赞动画,用户可能会玩得不亦乐乎,这个时候可能会对后端服务器造成一定的压力,因为每次点赞与取消点赞都会发起网络请求,假如很多用户同时在玩这个点赞动画,服务器可能会不堪重负。
和前一个例子的防抖动思路差不多,我们首先想到需要防抖动:
1 | boolean like; |
写到这个份上,其实已经可以解决服务器压力过大的问题了,但是还是有优化空间,假设当前是已赞状态,用户快速点击 2 下,按照上面的代码,还是会发送一次点赞的请求,由于当前是已赞状态,再发送一次点赞请求是没有意义的,所以我们优化的目标就是将这一类事件过滤掉:
1 | Observable<Boolean> debounced = likeAction.debounce(1000, TimeUnit.MILLISECONDS); |
zipWith操作符可以把两个Observable发射的相同序号(同为第 x 个)的元素,进行运算转换,得到的新元素作为新的Observable对应序号所发射的元素。参考资料:ZipWith
上面的代码,我们可以看到,首先我们对事件流做了一次 debounce 操作,得到 debounced 事件流,然后我们把 debounced 事件流和 debounced.startWith(like) 事件流做了一次 zipWith 操作。相当于新的这个 Observable 中发射的第 n 个元素(n >= 2)是由 debounced 事件流中的第 n 和 第 n-1 个元素运算得到的(新的这个 Observable 中发射的第 1 个元素是由 debounced 事件流中的第 1 个元素和原始点赞状态 like 运算而来)。
运算的结果是得到一个 Pair 对象,它是一个双布尔类型二元组,二元组第一个元素为 true 代表这个事件不该被忽略,应该被观察者观察到;若为 false 则应该被忽略。二元组的第二个元素仅在第一个元素为 true 的情况下才有意义,true 表示应该发起一次点赞操作,而 false 表示应该发起一次取消点赞操作。上面提到的“运算”具体运算的规则是,比较两个元素,若相等,则把二元组的第一个元素置为 false,若不相等,则把二元组的第一个元素置为 true, 同时把二元组的第二个元素置为 debounced 事件流发射的那个元素。
随后的 flatMap 操作符完成了两个逻辑,一是过滤掉二元组第一个元素为 false 的二元组,二是把二元组转化回最初的 Boolean 事件流。其实这个逻辑也可由 filter 和 map 两个操作符配合完成,这里为了简单用了一个操作符。
虽然上面用了不少篇幅解释了每个操作符的意义,但其实核心思想是简单的,就是在原先 debounce 操作符的基础上,把得到的事件流里每个元素和它的上一个元素做比较,如果这个元素和上个元素相同(例如在已赞状态下再次发起点赞操作), 就把这个元素过滤掉,这样最终的观察者里只会在在真正需要改变点赞状态的时候才会发起网络请求了。
我们考虑用 Callback 实现相同逻辑,虽然比较本次操作与上次操作这样的逻辑通过 Callback 也可以做到,但是 debounce 这个操作符完成的任务,如果要使用 Callback 来实现就非常复杂了,我们需要定义一个计时器,还要负责启动与关闭这个计时器,我们的 Callback 内部会掺杂进很多和观察者本身无关的逻辑,相比 RxJava 版本的纯粹相去甚远。
情景三:检测双击事件
首先,我们需要定义双击事件,不妨先规定两次点击小于 500 毫秒则为一次双击事件。我们先使用 Callback 的方式实现:
1 | long lastClickTimeStamp; |
上面的代码很容易理解,我们引入一个中间变量 lastClickTimeStamp, 通过比较点击事件发生时和上一次点击事件的时间差是否小于 500 毫秒,来确认是否发生了一次双击事件。那么如何通过 RxJava 来实现呢?就和上一个例子一样,我们可以在时间维度对 Observable 发射的事件进行重新组织,只过滤出与上次点击事件间隔小于 500 毫秒的点击事件,代码如下:
1 | Observable<Long> clicks = RxView.clicks(btn) |
我们再一次用到了 zipWith 操作符来对事件流自身相邻的两个元素做比较,另外这次代码中使用了 share 操作符,用来保证点击事件的 Observable 被转为 Hot Observable。
在
RxJava中,Observable可以被分为Hot Observable与Cold Observable,引用《Learning Reactive Programming with Java 8》中一个形象的比喻(翻译后的意思):我们可以这样认为,Cold Observable在每次被订阅的时候为每一个Subscriber单独发送可供使用的所有元素,而Hot Observable始终处于运行状态当中,在它运行的过程中,向它的订阅者发射元素(发送广播、事件),我们可以把Hot Observable比喻成一个电台,听众从某个时刻收听这个电台开始就可以听到此时播放的节目以及之后的节目,但是无法听到电台此前播放的节目,而Cold Observable就像音乐 CD ,人们购买 CD 的时间可能前后有差距,但是收听 CD 时都是从第一个曲目开始播放的。也就是说同一张 CD ,每个人收听到的内容都是一样的, 无论收听时间早或晚。
仅仅是上面这个双击检测的例子,还不能体现 RxJava 的优越性,我们把需求改得更复杂一点:如果用户在“短时间”内连续多次点击,只能算一次双击操作。这个需求是合理的,因为如果按照上面 Callback 的写法,虽然可以检测出双击操作,但是如果用户快速点击 n 次(间隔均小于 500 毫秒,n >= 2), 就会触发 n - 1 次双击事件,假设双击处理函数里需要发起网络请求,会对服务器造成压力。要实现这个需求其实也简单,和上一个例子类似,我们用到了 debounce 操作符:
1 | Observable<Object> clicks = RxView.clicks(btn).share() |
buffer操作符接受一个Observable为参数,这个Observable所发射的元素是什么不重要,重要的是这些元素发射的时间点,这些时间点会在时间维度上把原来那个Observable所发射的元素划分为一系列元素的组,buffer操作符返回的新的Observable发射的元素即为那些“组”。
参考资料: Buffer
上面的代码通过 buffer 和 debounce 两个操作符很巧妙的把点击事件流转化为了我们关心的 “短时间内点击次数超过 2 次” 的事件流,而且新的事件流中任意两个相邻事件间隔必定大于 500 毫秒。
在这个例子中,如果我们想要使用 Callback 去实现相似逻辑,代码量肯定是巨大的,而且鲁棒性也无法保证。
情景四:搜索框中需要根据用户输入内容显示搜索提示
以支付宝为例,当在搜索框输入“蚂蚁”关键词后,下方自动刷新和关键词相关的结果:
为了简化这个例子,我们不妨定义根据关键词搜索的接口如下:
1 | public interface Api { |
查询接口现在已经确定下来,我们考虑一下在实现这个需求的过程中需要考虑哪些因素:
- 防止用户输入过快,触发过多网络请求,需要对输入事件做一下防抖动。
- 用户在输入关键词过程中可能触发多次请求,那么,如果后一次请求的结果先返回,前一次请求的结果后返回,这种情况应该保证界面展示的是后一次请求的结果。
- 用户在输入关键词过程中可能触发多次请求,那么,如果后一次请求的结果返回时,前一次请求的结果尚未返回的情况下,就应该取消前一次请求。
综合考虑上面的因素以后,我们使用 RxJava 实现的对应的代码如下:
1 | RxTextView.textChanges(input) |
switchMap这个操作符与flatMap操作符类似,但是区别是如果原Observable中的两个元素,通过switchMap操作符都转为Observable之后,如果后一个元素对应的Observable发射元素时,前一个元素对应的Observable尚未发射完所有元素,那么前一个元素对应的Observable会被自动取消订阅,尚未发射完的元素也不会体现在switchMap操作符调用后产生的新的Observable发射的元素中。参考资料:SwitchMap
我们分析上面的代码,可以发现: debounce 操作符解决了问题 1,switchMap 操作符解决了问题 2、3。这个例子可以很好的说明,RxJava 的 Observable 可以通过一系列操作符从时间的维度上重新组织事件,从而简化观察者的逻辑。这个例子如果使用 Callback 来实现,肯定是十分复杂的,需要设置计时器以及一堆中间变量,观察者中也会掺杂进很多额外的逻辑,用来保证事件与事件的依赖关系。
RxJava 的维度
在前面两小节中,我们解读了很多案例,最终得出结论:RxJava 通过 Observable 这个统一的接口,对其相关的事件,在空间维度和事件维度进行重新组织,来简化我们日常的事件驱动编程。前文中提到:
有了 Observable 以后的 RxJava 才刚刚插上了想象力的翅膀。
RxJava 所有想象力的基石和源泉在于 Observable 这个统一的接口,有了它,配合我们各种各样的操作符,才可以在时间空间维度玩出花样。
我们回想一下原先我们基于 Callback 的编程范式:
1 | btn.setOnClickListener(v -> { |
在基于 Callback 的编程范式中,我们的 Callback 是 没有维度 的。它只能够 响应孤立的事件,即来一个事件,我处理一个事件。假设同一个事件前后存在依赖关系,或者不同事件之间存在依赖关系,无论是事件维度还是空间维度,如果我们还是继续用 Callback 的方式处理,我们必然需要新增许多额外的数据结构来保存中间的上下文信息,同时 Callback 本身的逻辑也需要修改,观察者的逻辑会变得不那么纯粹。
但是 RxJava 给我们的事件驱动型编程带来了新的思路,RxJava 的 Observable 一下子把我们的维度拓展到了时间和空间两个维度。如果事件与事件间存在依赖关系,原先我们需要新增的数据结构以及在 Callback 内写的额外的控制逻辑的代码,现在都可以不用写,我们只需要利用 Observable 的操作符对事件在时间和空间维度进行重新组织,就可以实现一样的效果,而观察者的逻辑几乎不需要修改。
所以如果把 RxJava 的编程思想和传统的面向 Callback 的编程思想进行对比,用一个词形容的话,那就是 降维打击。
这是我认为目前大多数与 RxJava 有关的技术分享没有提到的一个非常重要的点,并且我认为这才是 RxJava 最精髓最核心的思想。RxJava 对我们日常编程最重要的贡献,就是提升了我们原先对于事件驱动型编程的思考的维度,让我们有一种大梦初醒的感觉,和这点比起来,所谓的 “链式写法” 这种语法糖什么的,根本不值一提。
生产者消费者模式中 RxJava 扮演的角色
无论是同步还是异步,我们日常的事件驱动型编程可以被看成是一种 “生产者——消费者” 模型: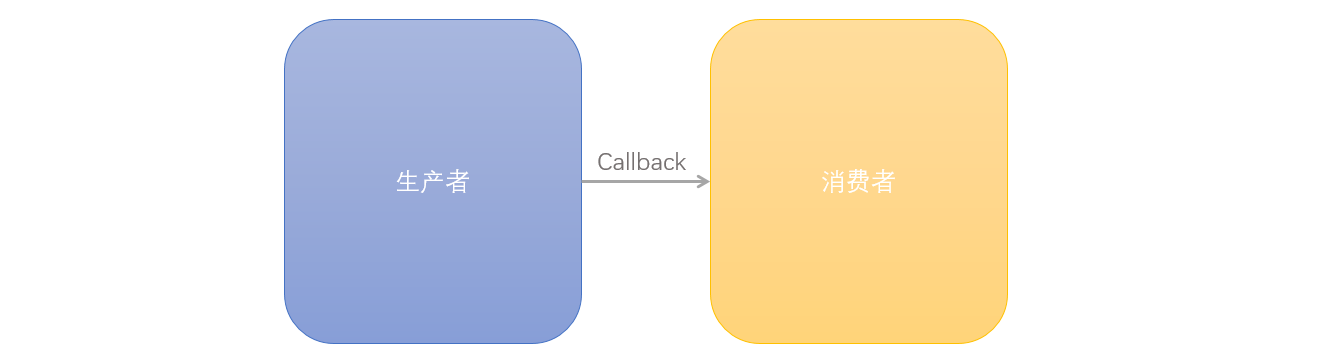
在异步的情况下,我们的代码可以被分为两大块,一块生产事件,一块消费事件,两者通过 Callback 联系起来。而 Callback 是轻量级的,大多数和 Callback 相关的逻辑就仅仅是设置回调和取消设置的回调而已。
如果我们的项目中引入了 RxJava ,我们可以发现,“生产者——消费者” 这个模型中,中间多了一层 RxJava 相关的逻辑层: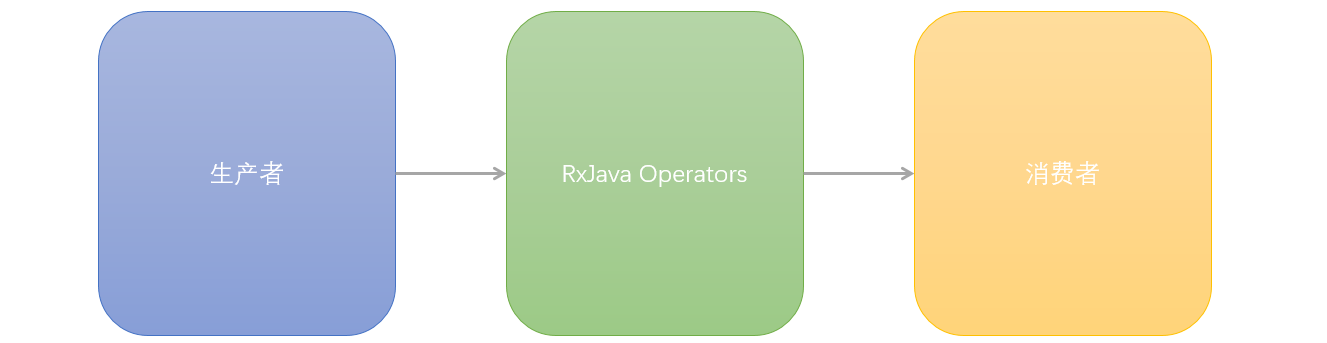
而这一层的作用,我们在之前的讨论中已经明确,是用来对生产者产生的事件进行重新组织的。这个架构之下,生产者这一层的变化不会很大,直接受影响的是消费者这一层,由于 RxJava 这一层对事件进行了“预处理”,消费者这一层代码会比之前轻很多。同时由于 RxJava 取代了原先的 Callback 这一层,RxJava 这一层的代码是会比原先 Callback 这一层更厚。
这么做还会有什么其他的好处呢?首先最直接的好处便是代码会更易于测试。原先生产者和消费者之间是耦合的,由于现在引入了 RxJava,生产者和消费者之间没有直接的耦合关系,测试的时候可以很方便的对生产者和消费者分开进行测试。比如原先网络请求相关逻辑,测试就不是很方便,但是如果我们使用 RxJava 进行解耦以后,观察者仅仅只是耦合 Observable 这个接口而已,我们可以自己手动创建用于测试的 Observable,这些 Observable 负责发射 Mock 的数据,这样就可以很方便的对观察者的代码进行测试,而不需要真正的去发起网络请求。
取消订阅与 Scheduler
取消订阅这个功能也是我们在观察者模式中经常用到的一个功能点,尤其是在 Android 开发领域,由于 Activity 生命周期的关系,我们经常需要将网络请求与 Activity 生命周期绑定,即在 Activity 销毁的时候取消所有未完成的网络请求。
常规面向 Callback 的编程方式我们无法在观察者这一层完成取消订阅这一逻辑,我们常常需要找到事件生产者这一层才能完成取消订阅。例如我们需要取消点击事件的订阅时,我们不得不找到点击事件产生的源头,来取消订阅:
1 | btn.setOnClickListener(null); |
然而在 RxJava 的世界里,取消订阅这个逻辑终于下放到观察者这一层了。事件的生产者需要在提供 Observable 的同时,实现当它的观察者取消订阅时,它应该实现的逻辑(例如释放资源);事件的观察者当订阅一个 Observable 时,它同时会得到一个 Disposable ,观察者希望取消订阅事件的时候,只需要通过这个接口通知事件生产者即可,完全不需要了解事件是如何产生的、事件的源头在哪里。
至此,生产者和消费者在 RxJava 的世界里已经完成了彻底的解耦。除此以外,RxJava 还提供了好用的线程池,在 生产者——消费者 这个模型里,我们常常会要求两者工作在不同的线程中,切换线程是刚需,RxJava 完全考虑到了这一点,并且把切换线程的功能封装成了 subscribeOn 和 observerOn 两个操作符,我们可以在事件流处理的任何时机随意切换线程,鉴于这一块已经有很多资料了,这里不再详细展开。
面向 Observable 的 AOP:compose 操作符
这一块不属于 RxJava 的核心 Feature,但是如果掌握好这块,可以让我们使用 RxJava 编程效率大大提升。
我们举一个实际的例子,Activity 内发起的网络请求都需要绑定生命周期,即我们需要在 Activity 销毁的时候取消订阅所有未完成的网络请求。假设我目前已经可以获得一个 Observable<ActivityEvent>, 这是一个能接收到 Activity 生命周期的 Observable(获取方法可以借鉴三方框架 RxLifecycle,或者自己内建一个不可见 Fragment,用来接收生命周期的回调)。
那么用来保证每一个网络请求都能绑定 Activity 生命周期的代码应如下所示:
1 | public interface NetworkApi { |
如果您之前没有接触过
ObservableTransformer, 这里做一个简单介绍,它通常和compose操作符一起使用,用来把一个Observable进行加工、修饰,甚至替换为另一个Observable。
在这里我们封装了一个 bindToLifecycle 方法,它的返回类型是 ObservableTransformer,在 ObservableTransformer 内部,我们修饰了原 Observable, 使其可以在接收到 Activity 的 DESTROY 事件的时候自动取消订阅,这个逻辑是由 takeUntil 这个操作符完成的。其实我们可以把这个 bindToLifecycle 方法抽取出来,放到公共的工具类,这样所有的 Activity 内部发起的网络请求,都只需要加一行 .compose(bindToLifecycle()) 就可以保证绑定生命周期了,从此再也不必担心由于网络请求引起的内存泄漏了。
事实上我们还可以有更多玩法, 上面 ObservableTransformer 内部的 upstream 对象,就是一个 Observable,也就是说可以调用它的 doOnSubscribe 和 doOnTerminate 方法,我们可以在这两个方法里实现 Loading 动画的显隐:
1 | private <T> ObservableTransformer<T, T> applyLoading() { |
这样,我们的网络请求只要调用两个 compose 操作符,就可以完成生命周期的绑定以及与之对应的 Loading 动画的显隐了:
1 | networkApi.getAllPhotos() |
操作符 compose 是 RxJava 给我们提供的可以面向 Observable 进行 AOP 的接口,善加利用就可以帮我们节省大量的时间和精力。
RxJava 真的让你的代码更简洁?
在前文中,我们还留了一个问题尚未解答:RxJava 真的更简洁吗?本文中列举了很多实际的例子,我们也看到了,从代码量看,有时候使用 RxJava 的版本比 Callback 的版本更少,有时候两者差不多,有时候 Callback 版本的代码反而更少。所以我们可能无法从代码量上对两者做出公正的考量,所以我们需要从其他方面,例如代码的阅读难度、可维护性上去评判了。
首先我想要明确一点,RxJava 是一个 “夹带了私货” 的框架,它本身最重要的贡献是提升了我们思考事件驱动型编程的维度,但是它与此同时又逼迫我们去接受了函数式编程。函数式编程在处理集合、列表这些数据结构时相比较指令式编程具有先天的优势,我理解框架的设计者,由于框架本身提升了我们对事件思考的维度,那么无论是时间维度还是空间维度,一连串发射出来的事件其实就可以被看成许许多多事件的集合,既然是集合,那肯定是使用函数式的风格去处理更加优雅。
原先的时候,我接触的函数式编程只是用于处理静态的数据,当我接触了 RxJava 之后,发现动态的异步事件组成的集合居然也可以使用函数式编程的方式去处理,不由地佩服框架设计者的脑洞大开。事实上,RxJava 很多操作符都是直接照搬函数式编程中处理集合的函数,例如:map, filter, flatMap, reduce 等等。
但是,函数式编程是一把双刃剑,一方面,这意味着你的团队都需要了解函数式编程的思想,另一方面,函数式的编程风格,意味着代码会比原先更加抽象。
比如上文中 “实现一个具有多种类型的 RecyclerView” 这个例子中, combineLatest 这个操作符,完成了原先 onOk() 方法、resultTypes、responseList 一起配合才完成的任务。虽然原先的版本代码不够内聚,不如 RxJava 版本的简练,但是如果从可阅读性和可维护性上来看,我认为原先的版本更好,因为我看到这几个方法和字段,可以推测出这段代码的意图是什么,可是如果是 combineLatest 这个操作符,也许我写的那个时候我知道我是什么意图,一旦过一段时间回来看,我对着这个这个 combineLatest 操作符可能就一脸懵逼了,我必须从这个事件流最开始的地方从上往下捋一遍,结合实际的业务逻辑,我才能回想起为什么当时要用 combineLatest 这个操作符了。
再举一个例子,在 “社交软件上消息的点赞与取消点赞” 这个例子中,如果我不是对这种把事件流中相邻事件进行比较的编码方式了如指掌的话,一旦隔一段时间,我再次面对这几个 debounce 、zipWith、flatMap 操作符时,我可能会怀疑自己写的代码。自己写的代码都如此,更何况大多数情况下我们需要面对别人写的代码。
这就是为什么 RxJava 写出的代码会更加抽象,因为 RxJava 的操作符是对我们处理业务逻辑的常用方法的高度抽象。 combineLatest 是对我们自己写的 onOk 等方法的抽象,zipWith 帮我们省略了本来要写的中间变量,debounce 操作符替代了我们本来要写的计时器逻辑。从功能上来讲两者其实是等价的,只不过 RxJava 给我们提供了高度抽象凝练,更加具有普适性的写法。
在本文前半部分,我们说到过,有的人认为 RxJava 是简洁的,而有的人的看法则完全相反,这件事的本质在于大家对 简洁 的期望不同,大多数人认为的简洁指得是代码简单好理解,而高度抽象的代码是不满足这一点的,所有很多人最后发现理解抽象的 RxJava 代码需要花更多的时间,反而不 “简洁” 。认为 RxJava 简洁的人所认为的 简洁 更像是那种类似数学概念上的那种 简洁,这是因为函数式编程的抽象风格与数学更接近。我们举个例子,大家都知道牛顿第二定律,可是你知道牛顿在《自然哲学的数学原理》上发表他的第二定律的时候的原始公式表示是什么样的吗:
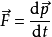
公式中的 p 表示动量,这是牛顿所认为的”简洁”,而我们大多数人认为简单好记的版本是 “物体的加速度等于施加在物体上的力除以物体的质量”。
这就是为什么,我在前面提前下了那个结论:对于大多数人,RxJava 不等于简洁,有时候甚至是更难以理解的代码以及更低的项目可维护性。
而目前大多数我看到的有关 RxJava 的技术文章举的所谓 “逻辑简洁” 或者是 “随着程序逻辑的复杂性提高,依然能够保持简洁” 的例子大多数都是不恰当的。一是仅仅停留在 Callback 的维度,举那种依次执行的异步任务的例子,完全没有点到 RxJava 对处理问题的维度的提升这一点;二是举的那些例子实在难以令人信服,至少我并没有觉得那些例子用了 RxJava 相比 Callback 有多么大的提升。
RxJava 是否适合你的项目
综上所述,我们可以得出这样的结论,RxJava 是一个思想优秀的框架,而且是那种在工程领域少见的带有学院派气息和理想主义色彩的框架,他是一种新型的事件驱动型编程范式。 RxJava 最重要的贡献,就是提升了我们原先对于事件驱动型编程的思考的维度,允许我们可以从时间和空间两个维度去重新组织事件。
此外,RxJava 好在哪,真的和“观察者模式”、“链式编程”、“线程池”、“解决 Callback Hell”等等关系没那么大,这些特性相比上面总结的而言,都是微不足道的。
反正我是不会用“简洁”、“逻辑简洁”、“清晰”、“优雅”那样空洞的字眼去描述 RxJava 这个框架的,这确实是一个学习曲线陡峭的框架,而且如果团队成员整体对函数式编程认识不够深刻的话,项目的后期维护也是充满风险的。
当然我希望你也不要因此被我吓到,我个人是推崇 RxJava 的,在我本人参与的项目中已经大规模铺开使用了 RxJava。本文前面提到过:
RxJava 是一种新的 事件驱动型 编程范式,它以异步为切入点,试图一统 同步 和 异步 的世界。
在我参与的项目中,我已经渐渐能感受到这种 “天下大同” 的感觉了。这就是为什么我能听到很多人都会说 “一旦用了 RxJava 就很难再放弃了”。
也许这时候你会问我,到底推不推荐大家使用 RxJava ?我认为是这样,如果你认为在你的项目里,Callback 模式已经不能满足你的日常需要,事件之间存在复杂的依赖关系,你需要从更高的维度空间去重新思考你的问题,或者说你需要经常在时间或者空间维度上去重新组织你的事件,那么恭喜你, RxJava 正是为你打造的;如果你认为在你的项目里,目前使用 Callback 模式已经很好满足了你的日常开发需要,简单的业务逻辑也根本玩不出什么新花样,那么 RxJava 就是不适合你的。
如果您对我的技术分享感兴趣,欢迎关注我的个人公众号:麻瓜日记,不定期更新原创技术分享,谢谢!:)
